
Overview
In this project, I explored how large language models (LLMs) can improve automatic essay scoring (AES) by using advanced techniques like many-shot prompting, jury of models, and model fine-tuning. My goal was to see how well these different approaches could tackle the challenges of scoring argumentative essays accurately and fairly. We used a dataset of 24,000 student-written essays to evaluate each method, and the results were compelling: using many-shot prompting with a model called Gemini 1.5 Flash achieved the best scoring accuracy, with a Quadratic Weighted Kappa (QWK) of 0.82, which indicates high agreement with human scores.
This project was part of a Kaggle competition, financed by the Bill & Melinda Gates Foundation and the Chan Zuckerberg Initiative. The competition aimed to push the boundaries of automated grading to help teachers provide timely feedback, especially in underserved communities. Vanderbilt University and The Learning Agency Lab partnered to host this event, using the largest open-access writing dataset aligned to current educational standards.
The Challenge
Grading essays is challenging. Teachers spend countless hours grading essays, and the manual process is:
Time-consuming: Up to 30 minutes per essay.
Subjective: Different teachers may give different scores.
Delayed Feedback: Students wait days or weeks for grades.
Effective AES systems have the potential to save educators time and help provide more frequent feedback to students. Given the advancements in LLMs, I wanted to investigate how we could best leverage them for essay scoring and which techniques yield the most reliable results.
Our Solution
We built and tested three different AI approaches:
1. Teaching AI with Examples
I used Gemini 1.5 Flash, a LLM with a large context window that can process up to 1 million tokens at once. I provided the model with 3,000 example essays along with their corresponding scores to improve the essay scoring process.

Result:
This many-shot approach significantly improved performance, achieving a QWK of 0.82, much better than the baseline score of 0.59 when using the model without examples (zero-shot). The inclusion of multiple scoring examples allowed the model to understand nuances better and make more informed decisions (Agarwal et al., 2024).
2. AI Grading Panel
Instead of relying on a single model, I tested the effectiveness of combining the scores from multiple smaller models. Specifically, I used Mixtral-8x7b-Instruct-v0.1, Gemini 1.5 Flash, and Llama-3-7b-chat. The models each provided a score, and the final score was determined through majority voting and averaging.
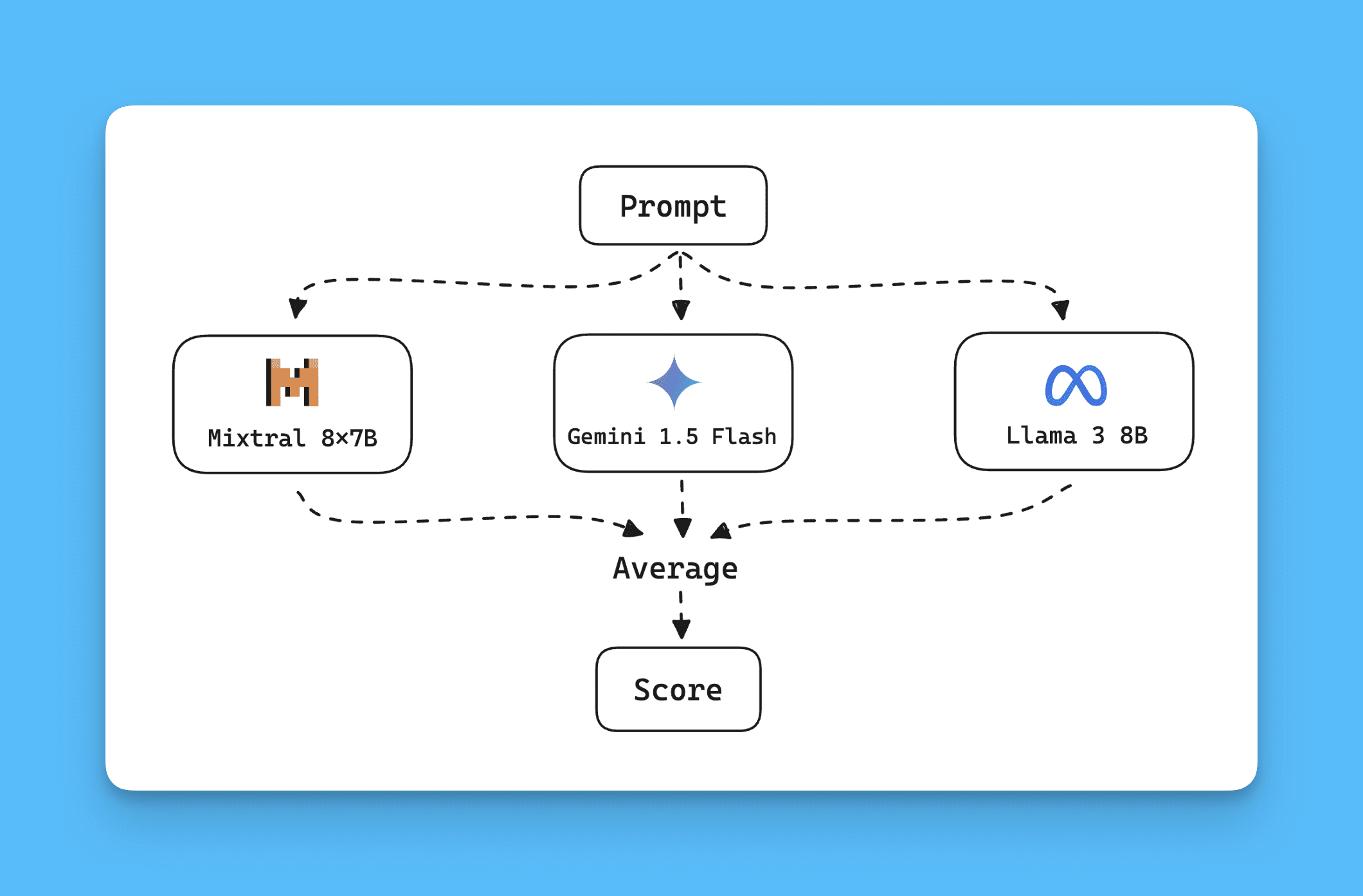
Result:
This approach achieved a QWK of 0.76. It demonstrated that combining models can reduce bias and yield more reliable scoring, aligning with recent findings in ensemble model strategies (Verga et al., 2024).
3. Custom-Trained AI
I fine-tuned Llama-3 using Low-Rank Adaptation (LoRA), a method designed to adapt a subset of a large model's parameters while keeping most weights unchanged. This process aimed to make the model more specific to essay scoring.

Result:
Unfortunately, fine-tuning did not yield the expected results, resulting in a QWK of 0.31, which was quite low compared to other approaches. This might have been due to overfitting, as the model seemed to assign the median score (3 out of 6) too frequently due to the distribution imbalance in the training data.
Technical Details
Dataset
We used the Learning Agency Lab - Automated Essay Scoring 2.0 dataset, consisting of 24,000 argumentative essays, each scored on a scale from 1 to 6.
Metric
We used the Quadratic Weighted Kappa (QWK) to measure scoring agreement, as it reflects the degree of similarity between model-generated scores and human evaluators, considering both actual values and penalties for disagreements (Attali & Burstein, 2006):
$$\kappa = 1 - \frac{\sum_{i,j} w_{ij} O_{ij}}{\sum_{i,j} w_{ij} E_{ij}} $$
where:
• $O_{ij}$ = Number of essays given grade i by human and j by AI
• $E_{ij}$ = Expected count under random chance
• $w_{ij}$ = Weight matrix measuring distance between grades
Model Ensemble
In the jury of models approach, I leveraged majority voting and average score methods to make decisions. Ensemble learning reduced the overall bias and produced more robust results compared to a single large model like GPT-4. This outcome aligns with findings that highlight ensemble techniques often outperform single models by balancing model-specific biases (Verga et al., 2024).
Fine-Tuning Challenges
While fine-tuning Llama-3, I used 10% parameter updates via LoRA. Despite the efficiency of LoRA for fine-tuning, it struggled in this case, which could be attributed to the limited dataset size or insufficient adaptation to essay complexity. A critical observation was the model's tendency to predict the score "3" too often—this points to overfitting towards the training data's most frequent score, underlining the importance of a well-balanced training set.
Key Findings
Many-Shot Prompting is King: Providing models with a large number of examples improved performance substantially. It highlights that context and examples are crucial in helping LLMs perform well on subjective tasks like essay scoring.
Model Ensembling Reduces Bias: Aggregating the predictions of different models, even smaller ones, can yield better, more reliable results compared to a single, more powerful model. This reduces the influence of model-specific biases and errors.
Challenges of Fine-Tuning: The fine-tuning process remains tricky. While LoRA offers a resource-efficient way to adapt large models, it showed limited success in our scenario, partly due to issues like overfitting and imbalanced training data.


