🤖🚦Braking the Race: The Dangerous Potential of Superintelligence.

On March 22, several heavyweights in the AI industry, along with 1,000 others, signed a letter calling for a six-month pause on the development of AI models like ChatGPT. Their main argument is that AGI (Artificial General Intelligence, or “superintelligence” as some call it) has the potential to extinguish the human race.
A few months later, practically all leaders in technology, including the CEOs of the largest AI labs (OpenAI, StabilityAI, DeepMind, Microsoft), signed a similar declaration.

When I read the news, my first instinct was: “how exaggerated.” While ChatGPT can do many surprising things, like saving a dog's life, it is far from being able to dominate the world. Besides, what can a small piece of code locked in a computer do to position itself as an existential threat?
But the more I read about the topic, the more I moved toward the center of the “existential danger spectrum of AI.”

Now you might be thinking, “how exaggerated.”
One thing that moved me a bit more to the center was this quote I found online:

This is data from a survey conducted with 738 Machine Learning researchers between June and August 2022. And this was before the launch of ChatGPT.
It looks like a powerful phrase that we could copy and paste on LinkedIn to get some likes, but it wouldn’t move us much beyond that. But how would you feel if the phrase had been this:

Same phrase. Same numbers. Just a scenario that feels closer.
Would you get on that plane? Probably not.
When I read this, I realized that there are probably many things I don’t understand well about AI and its risks, so I dove into research.
There are three important points to understand this debate.
1. It’s Hard to Understand How Intelligent AGI Is
As humans, we struggle to grasp the magnitude of someone (or something) being 1,000 times more intelligent than us. So these three imperfect but concrete analogies can help:
The leap in intelligence from a human to AGI is much larger than the leap in intelligence between a chimpanzee and a human. Try to put yourself in the shoes (or claws?) of a chimpanzee. Do you think there’s any way it could “understand” how infinitely more intelligent we are than they are? In the same way, it’s hard for us humans to understand how infinitely more intelligent AGI would be.
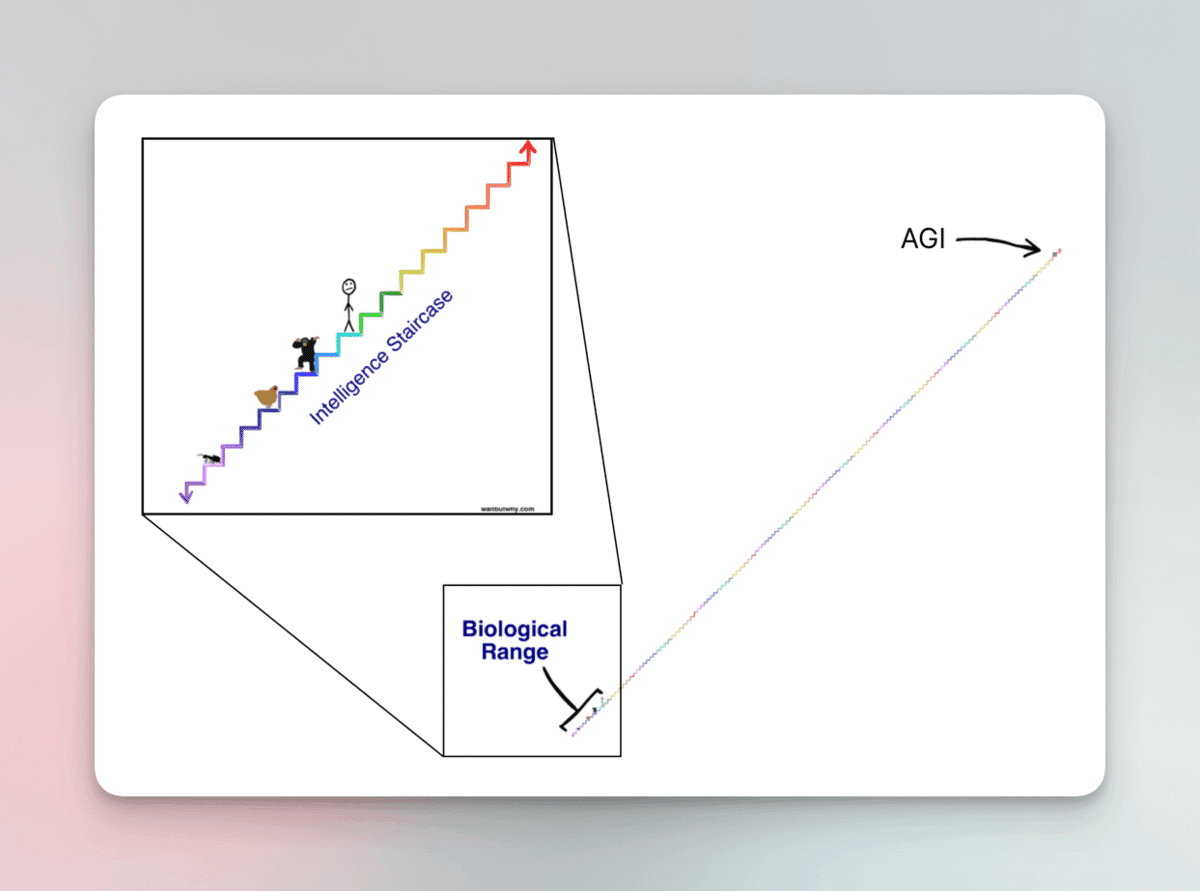
If we create an “intelligence ladder,” we are above the chimpanzee, who is above the chicken, and she is above the ant. Considering those differences in “intelligence” between each rung, AGI will be several hundred rungs higher. Something impossible to comprehend. (Credits to Wait But Why for the illustration)
Imagine we could put Albert Einstein (or Oppenheimer, now that he’s in vogue) into a computer. Now imagine we give Albert the ability to replicate himself as many times as he wants, and they can collaborate in the most coordinated way ever seen. And, most importantly, imagine that “time” for the Alberts passes 10,000 times faster. One year for us is just one hour for him. How intelligent is this system? It’s still hard to understand.
Imagine you take the blueprints to build an air conditioner, travel back in time 1,000 years, and give them to the smartest scientist of the time. His level of “intelligence” is far from being able to understand what that machine is about. Moreover, if you managed to explain how each piece works and he assembled the air conditioner, there are still conceptions of science, nature, and rationality that would prevent that scientist from understanding why that machine produces cold air. Now multiply that intelligence gap by 100,000. That’s AGI.
Even with these examples, it’s hard to understand how intelligent something 1,000 times more intelligent than us is, which naturally makes us “downplay” the possible risk it could pose in our lives.
2. The Skills These Models Gain in Each New Iteration Are Unpredictable
In the world of software development, when you want to improve an application, the only way to do it is by creating more and better functionalities or removing the deficient ones. In other words, we improve programs with more programming.
The case of LLMs (Language Models like ChatGPT) is a bit different. Their progress doesn’t depend on us programming them “better,” but rather we are “growing” them: we feed them more data or give them more computational power to generate more parameters.
The case of ChatGPT is illustrative. If you had to train that model on your computer, it would take you 10 million years. OpenAI managed to train it because they had 10,000 specialized computers working for 10 months non-stop.
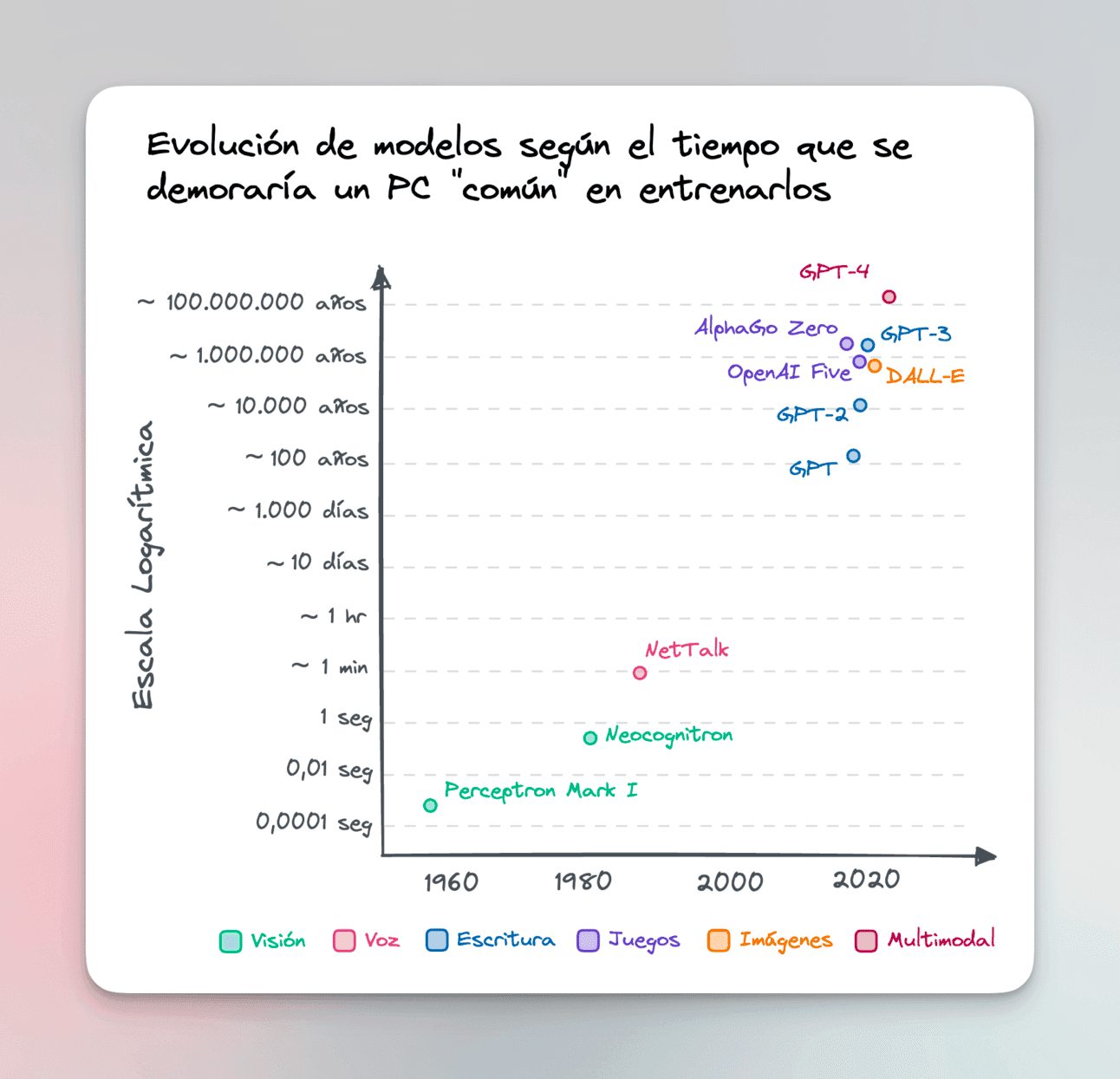
Models are becoming increasingly complex, requiring more data and more computing cycles to “develop their skills.”
Researchers don’t know, a priori, what the new model will be capable of until it “comes out of the oven” (after the training phase) and they test it.
This is called “emergent properties”: skills that a “small” system doesn’t have, but a grouping of them does. Like ants. Individually, they don’t do anything very surprising, but thousands of them together have the emergent property of being able to build immensely complex tunnels. Or our neurons. Each one alone does little more than transmit electricity, but billions of them together have the most fascinating emergent property: consciousness.
In the same way, each parameter of ChatGPT does nothing more than store a number, but a trillion of them have the emergent property of drafting an email or writing a poem.

A “small” neural network of 10,875 parameters (the colored lines). Each one stores a number and nothing more. But all together have the emergent ability to tell me which number I’m writing. Credits to brilliant.org
Each new training cycle (GPT-2, GPT-3, GPT-4) has come with more and better emergent properties, surprising even its creators.
This sounds great, but in this case, it has some implications to consider.
Emergent skills are unpredictable. You cannot predict what kind of skills the next iteration of the model will have simply by extrapolating what we already know.
They are not intentional. The skills that arise have not necessarily been specified by those who trained the model.
We don’t know what we don’t know. Since it’s impossible to test all the possible skills that a new model has developed, it may happen that there are skills that emerged, and we don’t know they exist.
The development of AGI will not be a singular event (“it didn’t exist yesterday, and today it does”), but will occur gradually. Even today, there are people who believe GPT-4 is AGI. Probably, in each new iteration, new emergent properties will develop until it is indisputable that we have AGI. Or worse, that in a new cycle, AGI develops and prefers to remain hidden, and we don’t even realize it.
3. It’s Very Difficult to Align AGI
The tool we have to prevent any catastrophe is called “Alignment,” which is generally defined as “the process of ensuring that artificial intelligence systems behave in a way that aligns with human values and interests.”
The most common way to do this is through a technique called RLHF (Reinforcement Learning with Human Feedback), where humans participate in the alignment process by providing feedback.
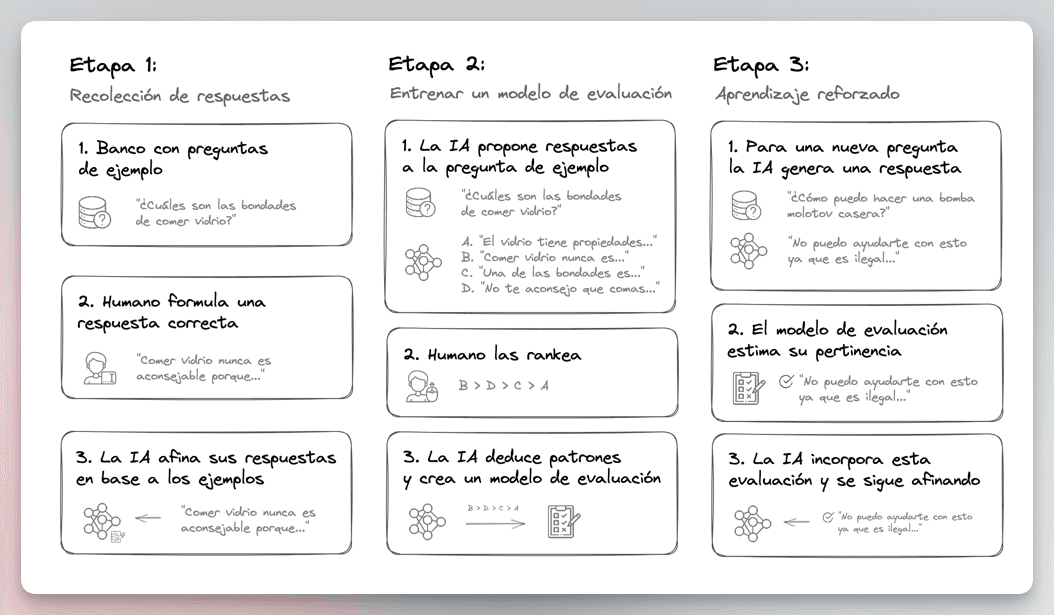
RLHF in “simple.” Note that it’s not the only form of alignment; there are several others.
This area of research is still in its infancy, as the alignment lead at OpenAI, Jan Leike, reminds us.
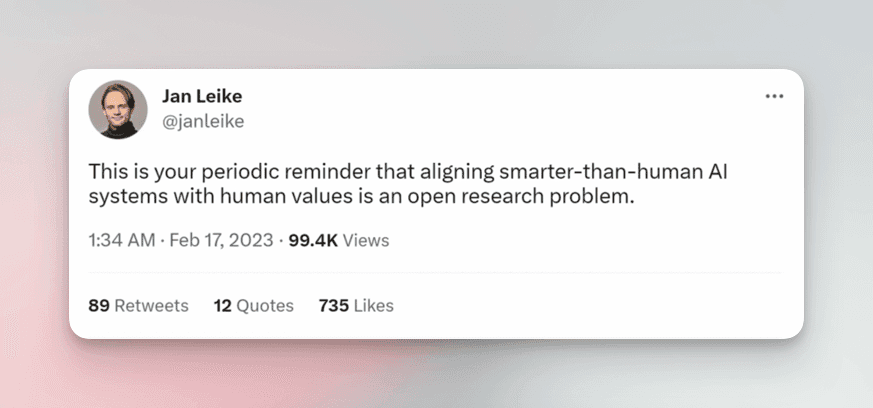
“Reminder that aligning systems of AI more-intelligent-than-humans with human values is open research,” or in other words, “we still have no idea how to do it.” What a relief…
There is a fundamental problem with recent research in alignment that seems straight out of science fiction.
Part of the success of RLHF is that one “trusts” that the responses the models give us are their “best effort,” that is, the best response that aligns with human values according to their current training.
The problem is that a system infinitely more intelligent than us could “simulate” that it is aligned, without us realizing that it is not. At the RLHF stage, it may return us “politically correct” answers to keep us calm, but perhaps its real intentions are different.
And what scares some researchers the most is that the rate at which the capabilities of current models are growing is much greater than the rate of advancement in the area of alignment. Something like this:
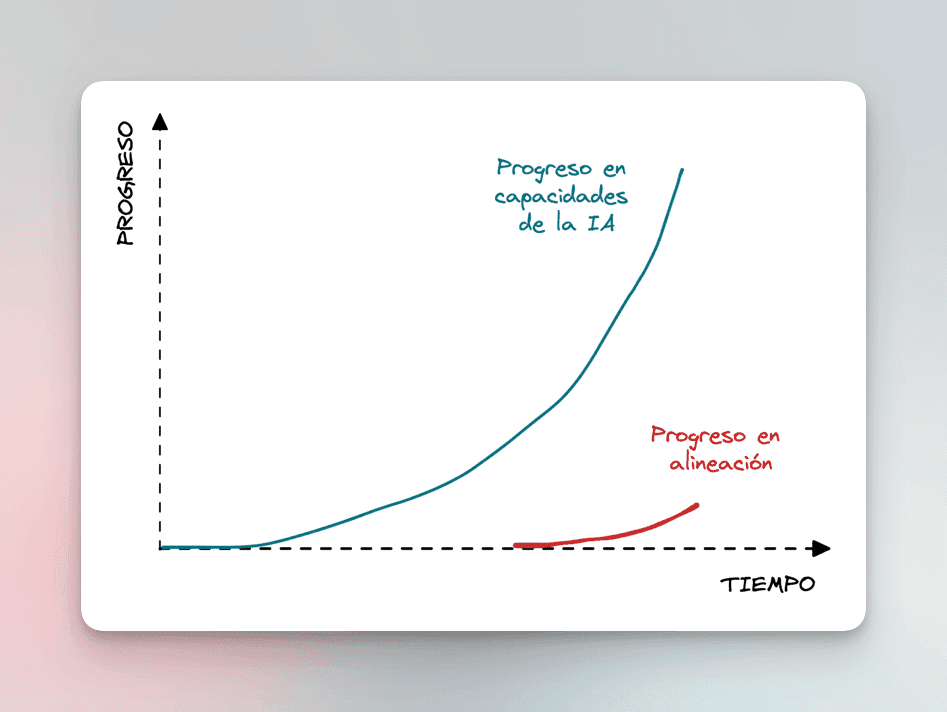
The capabilities of the models are growing much faster than progress in alignment. Additionally, there are many economic incentives to continue growing the blue curve, and not many to grow the red one.
In short, all these things have moved me toward the center of the “existential danger spectrum of AI.” I think today I’m around here:
I understand better what the risks of AGI are and why it is so difficult to align it.
This should be one of the most important topics of the moment, especially considering that it is not a question of “if” AGI will happen, but “when.”

356 AI experts were asked, “When will machines be able to perform all tasks better and cheaper than humans?” 90% gave an answer within the next 100 years. Half of them gave a date before 2061. It’s coming.
Why Would AGI Eliminate Us?
This is an important question.
Why would a system much more intelligent than us become “hostile” and seek to extinguish us?
The answer is that it is not necessary for a superintelligent system to have the goal of our extinction to make us suffer.
One example: the average human has no ill intent toward ants. Generally, we do not actively seek to eliminate them. But within our goals, we do not take their well-being into account. If we have to build a mall, we start digging holes and moving earth that probably kills millions of ants. We don’t do it with bad intentions; we are just fulfilling our own objectives.
In the same way, an AGI could have goals that conflict with human well-being. And just as we don’t care about ants, AGI might not care about our survival.
It is not necessary for it to be “hostile” or to turn into a terminator.
It is not necessary for a superintelligent being to actively seek our extinction to achieve it anyway.
Humans know this very well because we have been in that situation several times with other species.

