🌚🎯 The Dark Side of Optimization: The Struggle Between Perfection and Generalization

I am a compulsive optimizer.
When I want to do something, I set a goal, and my brain starts calculating the best way to achieve it.
This is sometimes useful in work contexts (how can I turn this project idea into a plan and execute it?), but not so useful when taken to the extreme (how much water should I put in the kettle to boil it as quickly as possible, but still have enough to fill the cup?).
In the second case, I probably spent more time/energy thinking about the right amount of water than the time I gained optimizing that (irrelevant) variable.
Today's post aims to answer this question: what is the optimal level of optimization?
In Machine Learning (ML), there is a concept that can help us answer it.
Don't close this post just yet. I promise not to get too technical.
Moreover, it’s worth staying until the end because this phenomenon can help us understand the problems in education, work, and knowledge creation.
Training Our First Model
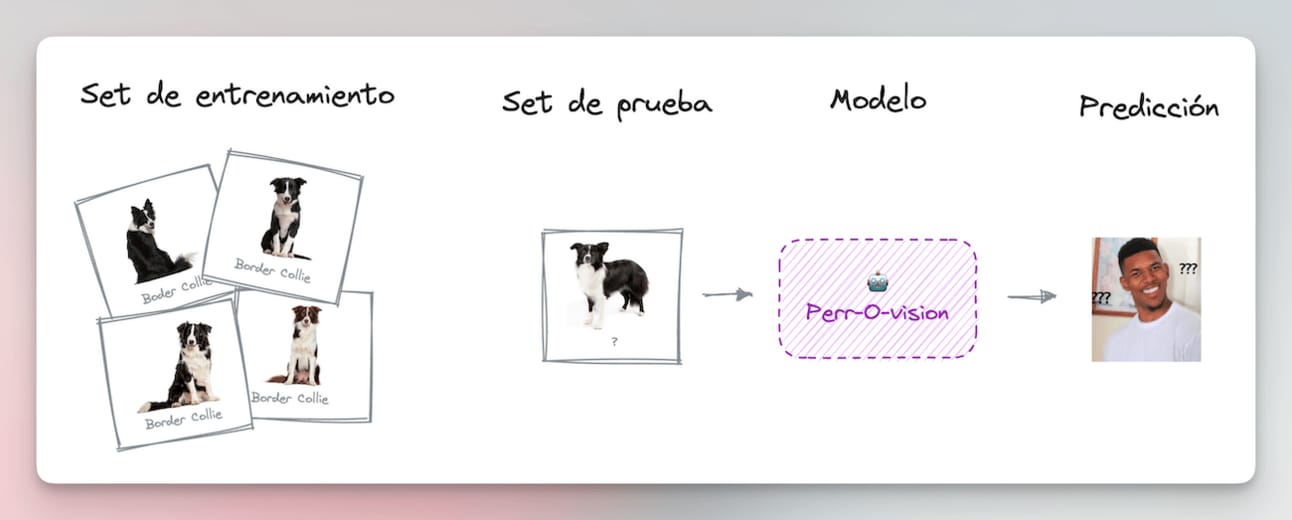
Let’s suppose we want to create an AI model that is very good at classifying images of dogs. We want to give it a photo of a dog and have the system tell us what breed it is.
The best way to train this model is with a technique called “Supervised Learning.” For the model to learn, you must provide it with a “training set” containing many labeled photos of dogs.
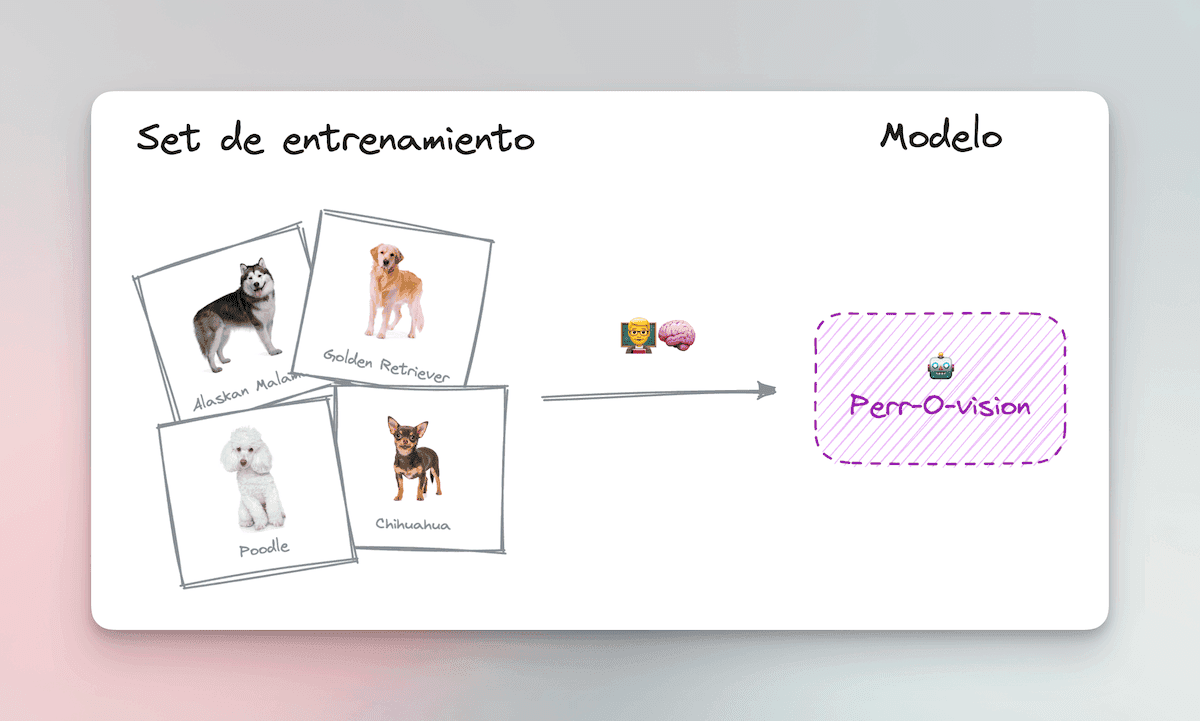
Something like this, but with tens of thousands of labeled images.
For each photo in the training set, the model tries to guess which breed it corresponds to.
At first, it is practically random, so it is very bad at guessing. But since it knows the correct answer (each photo has its label), it can improve itself so that next time it has a better chance of guessing correctly.
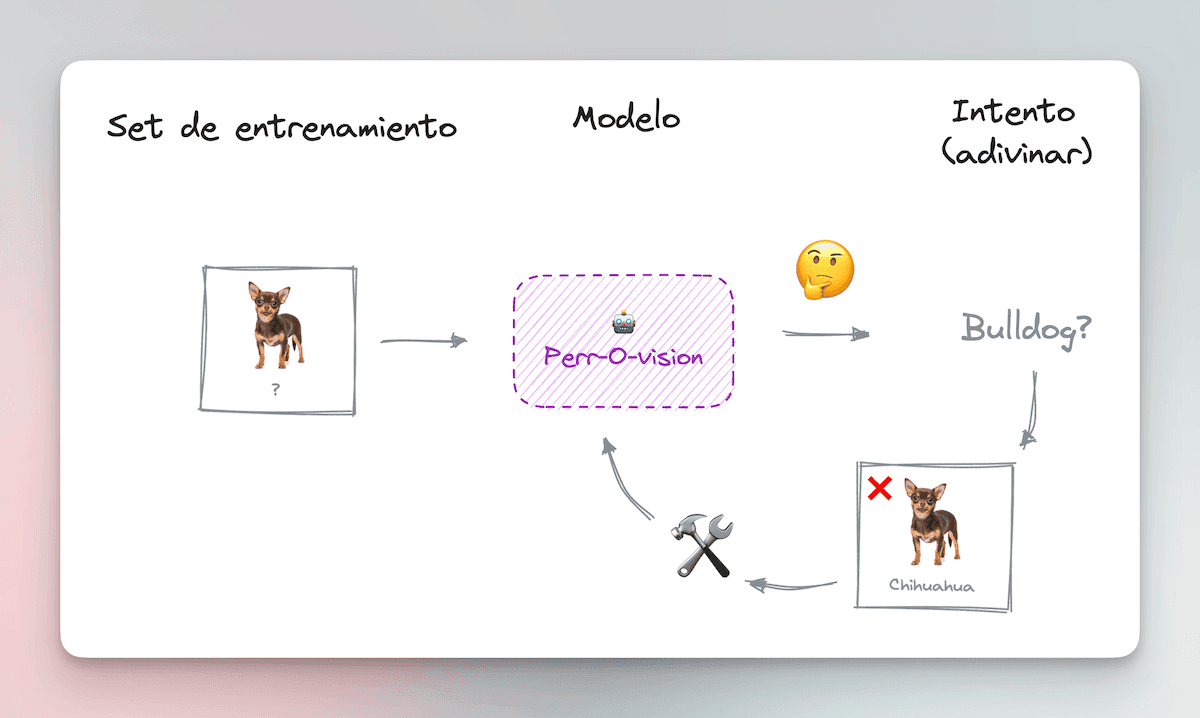
As time goes by, this trial-and-error learning improves its prediction ability. Our model becomes increasingly better at cataloging the dogs in the training set.
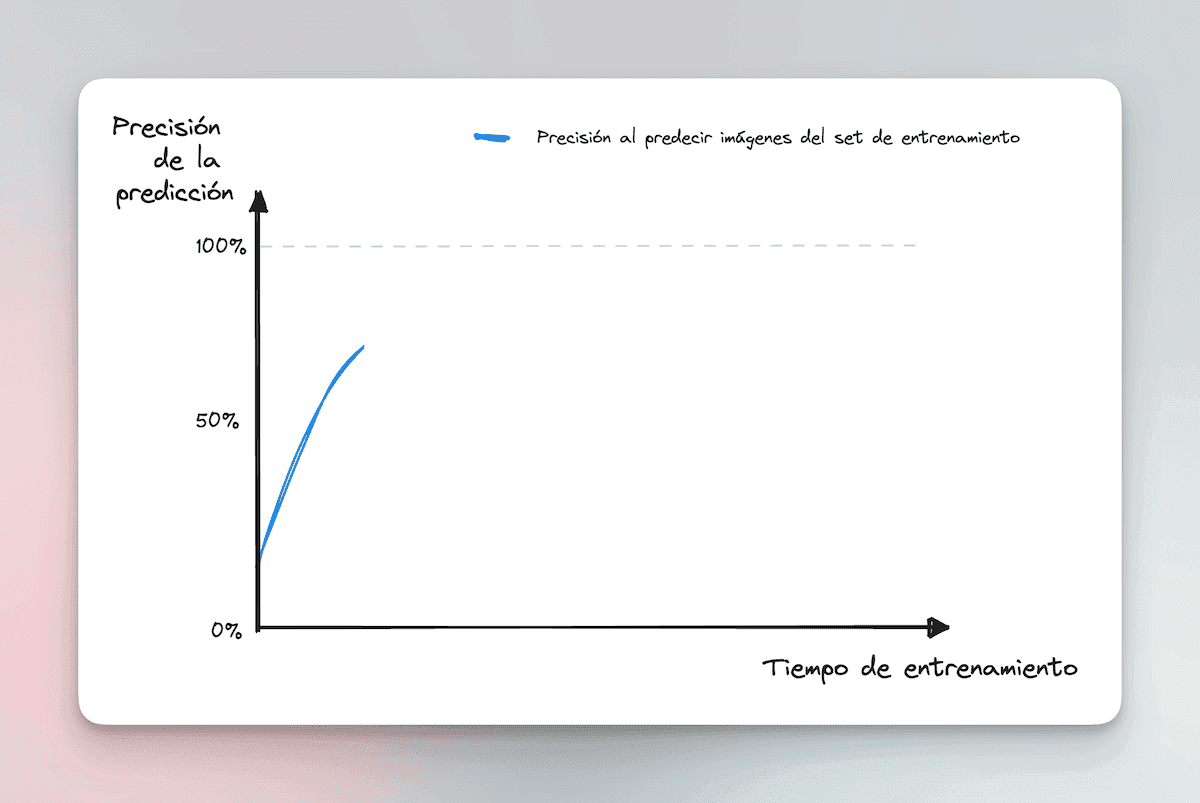
The more training time it gets, the more accurate it becomes at cataloging images from the training set.
Now that the model has become more accurate, it’s time to test it in the real world.
Instead of passing it the same images from the training set for it to guess, we will give it new images of dogs it has never seen before to see if it can generalize what it has learned.

And if all goes well, then our model should be relatively competent at cataloging the new images.
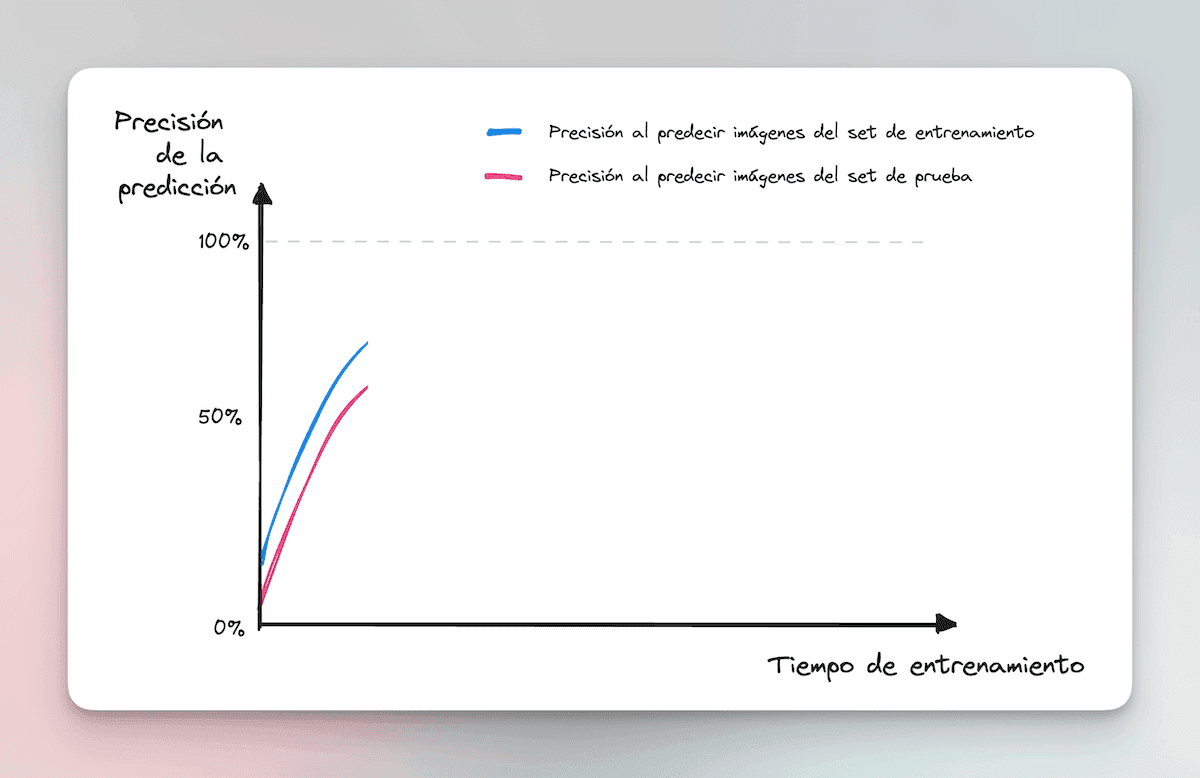
It will never be as good as when trying to catalog the images it already knows (training set), which is why the red curve is always below the blue one. But it’s a good start.
Now, if we keep training the model, something curious starts to happen.
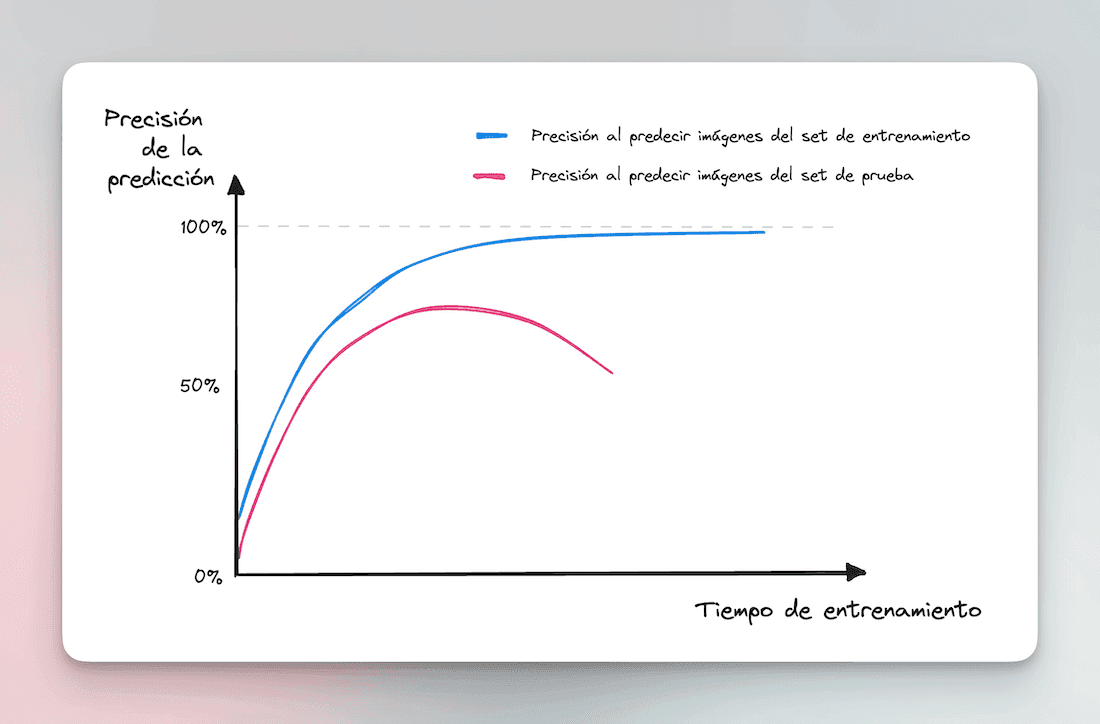
On one hand, the more computing time we give the model to keep “learning” about the training set, the better its prediction ability becomes, reaching almost 100% accuracy.
But its ability to catalog new images (test set) goes down the drain.
What’s happening here?
The Curse of “Overfitting”
What was our initial goal in creating this model?
To ensure it is very good at cataloging any image of a dog.
But it is impossible to optimize with that goal in mind because we will never be able to train the model on all the dog photos in the world.
To simplify, we use a proxy: a goal that resembles the original goal but is easier to manage. In our case: training the model on a subset of dog images that we hope is representative enough of reality.

Since the two sets are relatively similar, at first, the model is good at predicting images from both. But as the model becomes more “expert” in the training images, it becomes very good at cataloging
only
those images and very bad with
everything
else.
The peculiarities of the training set become accentuated with each additional learning cycle. Some features that it initially did not take into account (because they were irrelevant) begin to weigh more heavily in its decision.
In the world of Machine Learning, this is called “overfitting.” And it’s a real problem.
For example, if many of the photos of Border Collies in the training set are of sitting dogs, then the model might “learn” that this breed of dog is generally sitting.
When it sees a photo of a standing Border Collie, it may get confused and misclassify it.
The model starts to focus disproportionately on features that prevent it from generalizing.
We can summarize what happened as follows:
Real objective to optimize: a model that can catalog all dog photos by breed.
Proxy objective: it’s difficult to collect all the photos in the world, so we provide a representative subset.
Overfitting: if we try to optimize too much, the model starts to focus on irrelevant details of the training set and is unable to generalize to catalog real photos.
And Why Should I Care?
Now that you know the concept of overfitting, you will realize that it is applicable to many “complex” systems in our lives.
Some examples:
Education
Real objective to optimize: that students learn the subjects well.
Proxy objective: we cannot get inside children’s brains to see how much they have learned, so we use standardized tests to measure how much they know about each subject.
Overfitting: if an education system puts too much pressure on standardized tests, the search for optimizing their results makes students turn into robots very good at answering multiple-choice questions, but who may not have actually learned anything.

### Work
Real objective to optimize: that employees are productive and contribute to the success of the business.
Proxy objective: since it’s not always easy to measure productivity directly, indicators like time spent on work tasks or the number of completed tasks are often used.
Overfitting: if an employer focuses excessively on these metrics, it can foster a work culture where employees are constantly busy, filling their days with tasks or staying late doing nothing, but they may not be effectively contributing to the long-term growth or success of the business.

### Scientific Research
Real objective to optimize: to discover fundamental truths about the universe, develop useful technologies, and new medical therapies.
Proxy objective: the number of publications in scientific journals, often used to measure a researcher’s productivity.
Overfitting: scientists may feel tempted to conduct and publish only those experiments that will yield “publishable” results, avoiding risky or long-term research questions that could lead to more significant breakthroughs. Or, on the other hand, they may focus on publishing several short, low-value articles to increase their publication count.

### Digital Marketing
Real objective to optimize: Increase brand recognition and long-term sales.
Proxy objective: Number of clicks, impressions, or “likes” on social media posts.
Overfitting: An excessive focus on these metrics can lead to short-term marketing tactics that grab attention (the known “clickbait”), but do not generate brand loyalty or sustainable sales.

## Some Reflections
This parallel between Machine Learning and life itself leads me to think of three things:
When you optimize something, you are rarely optimizing the very thing you want to optimize. Generally, we choose a proxy objective that is representative of the overall goal but also distinct. When we want to optimize our physical condition, it’s impossible to take into account all the variables that result in a healthy life, so we choose one of them (going for a jog, eating well, or lifting weights) and use it as a proxy for the original goal.
When you over-optimize a proxy objective, you actually move further away from the original goal. “Overfitting” leads you to be very good at optimizing your proxy objective, but it takes you away from your original goal. If I chose to lift weights as a healthy alternative, and if I obsess over optimizing that objective, I will probably increase my muscle mass significantly, but at the cost of other markers that are also important for my physical condition (nutrition, flexibility, VO2 max, etc.).
If we return to the original question, “What is the optimal level of optimization?” the concept of overfitting gives us the answer: neither too little nor too much: in the middle. When we feel that an additional hour of optimization will take us away from the original goal, that’s when we need to adjust. In our example, reducing weightlifting hours (and losing those precious biceps) to dedicate hours to other activities where an hour of optimization still has a “positive pending” (there’s still room for growth).
I’ll close with a quote from Aristotle, who understood this long ago without the need for complicated analogies with Machine Learning: “Virtue manifests in passions and acts; and for passions and acts, excess in more is a fault; excess in less is equally reprehensible; only the mean is worthy of praise.”
P.S.: The central idea of this article and several examples were inspired by these two other articles (article 1 and article 2). I recommend following those creators if you’re interested in this topic.

